


Latency, cost, accuracy: pick two?🐰

We asked Gemini 2.5 and Claude 3.7 the same brain-twister:
“If Alice is twice as old as Bob was…” (you know the one 👵👦)
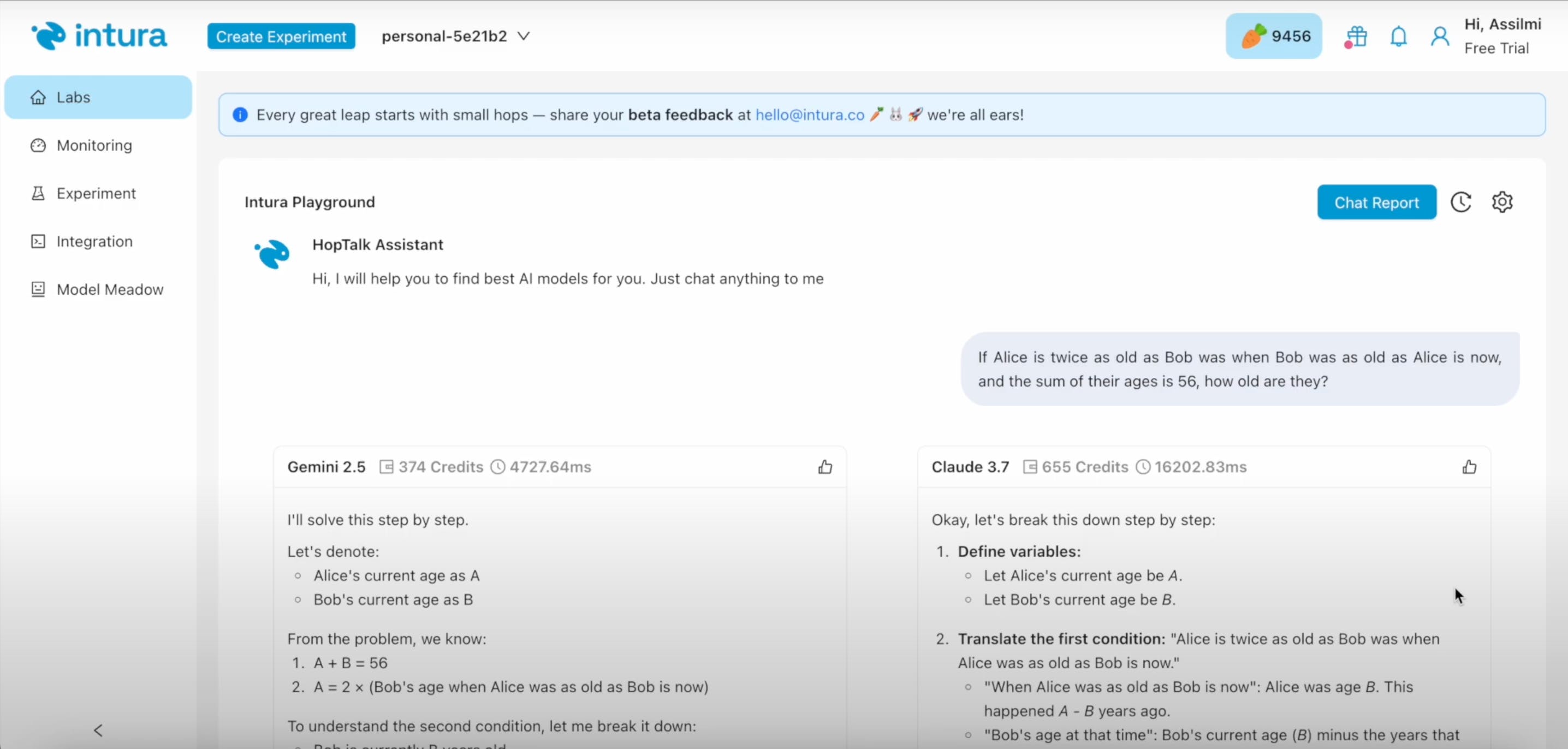
Both answered right.
But here’s what we’re wondering 👇
When you’re looking at LLM performance, what metric should come first?
Latency?
Token usage?
Cost?
Hallucination risk?
Just… vibes?
We’re building a monitoring layer on Intura to make this easy (and kinda fun).
What would you want to see first when your AI goes rogue?
Drop it in the replies 👇
#LLM #Monitoring #AItools #PromptEngineering #Intura
33 views
Replies
Strawberry