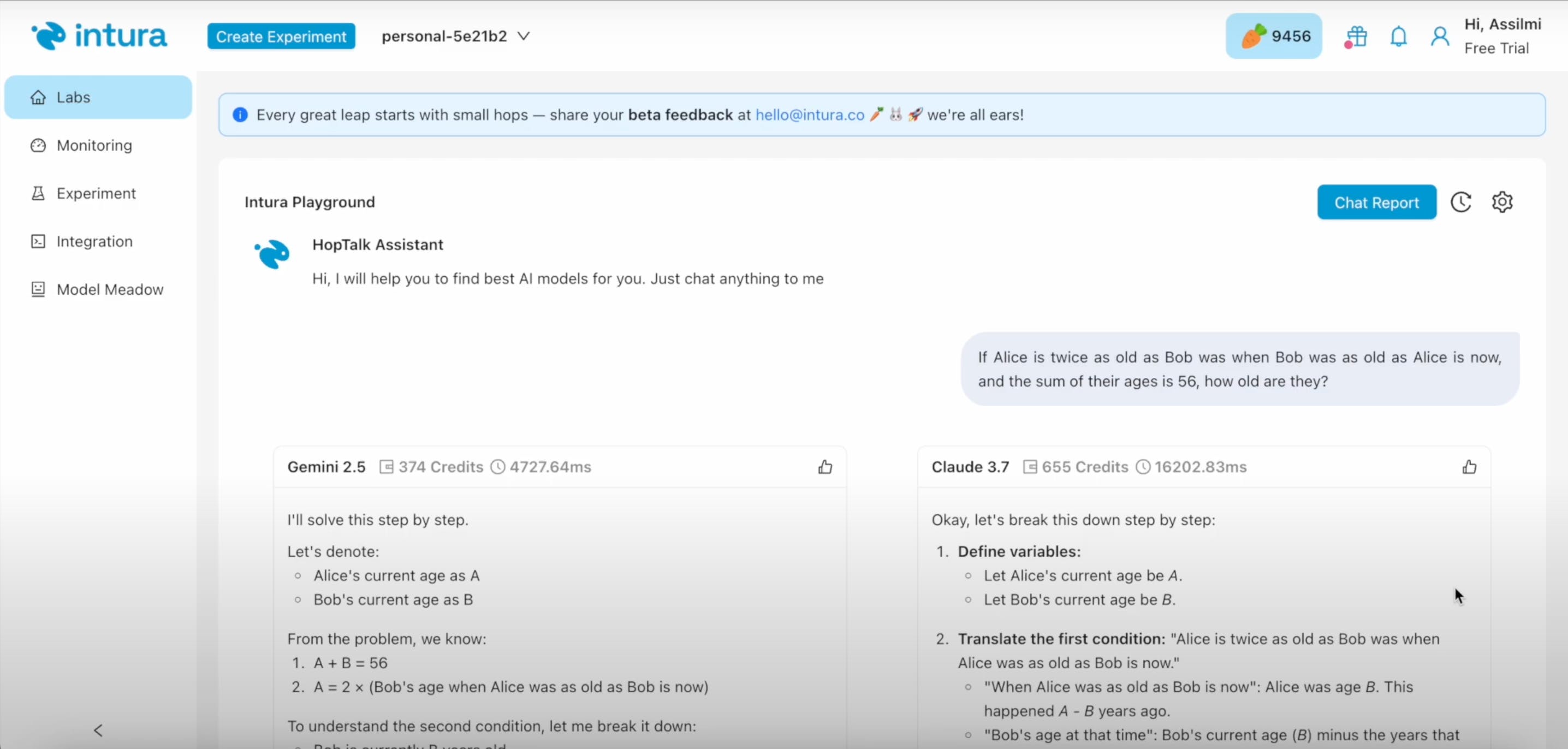
A platform that helps you compare, test, and optimize AI models, making it easier to select the best-performing and most cost-effective AI for their needs. This is our first launch and we would love to have your feedback on the beta! (we're all ears 🐰)