

Neum AI
Keep your vector database in sync with your data
130 followers
Keep your vector database in sync with your data
130 followers
Neum AI (https://neum.ai) is an ETL platform for LLM data. It helps companies connect and synchronize data into vector stores in real-time. No more chatbots that respond with stale information, with Neum vectors are always accurate and up to date.






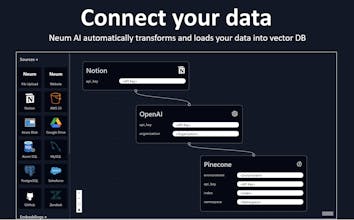
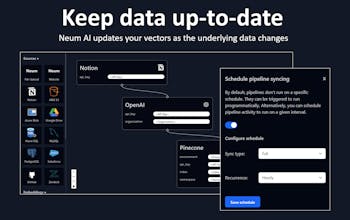








Neum AI
Voxme: AI coach, insights, guidance
Neum AI
Expert Remote