
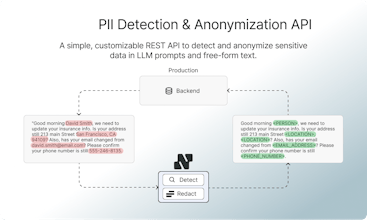
Neosync is an open source ETL platform with built-in data anonymization and synthetic data tools that developers use to: - anonymize production data so they can safely use it locally - detect & redact sensitive data in LLM prompts - generate synthetic data

Subscribe
Sign in











Neosync
Neosync
Onlook
Neosync