

Zebrium Autonomous Monitoring
Let machine learning catch software problems
2 followers
Let machine learning catch software problems
2 followers
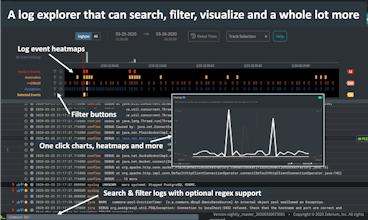
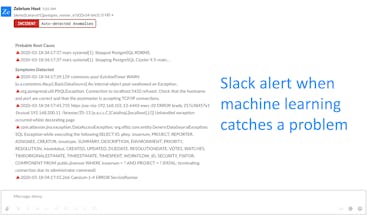
We live in a world where everything is being automated. But catching and understanding software problems still takes a lot of manual work. There's a better way! Let machine learning catch software problems and tell you what happened.












Zebrium Autonomous Monitoring
Zebrium Autonomous Monitoring
Zebrium Autonomous Monitoring