

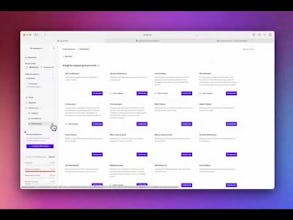
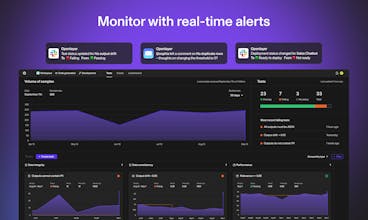
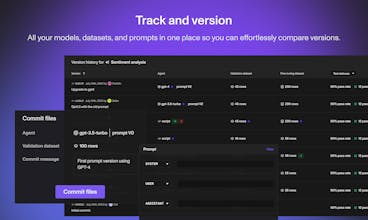
Openlayer is a powerful testing and observability platform for ML. It lets you collaborate with others on finding issues in models and data, debugging them, and committing new versions.
This is the 2nd launch from Openlayer. View more
Openlayer

Openlayer provides observability, evaluation, and versioning tools for LLMs and machine learning products.


Free Options
Launch Team










Openlayer
EnVsion AI
Openlayer
EnVsion AI
SprintsQ
Openlayer