

GPT-4o
Fast, intelligent, flexible GPT model
4.8•1.2K reviews•13K followers
Fast, intelligent, flexible GPT model
4.8•1.2K reviews•13K followers

GPT-4o (“o” for “omni”) is our versatile, high-intelligence flagship model. It accepts both text and image inputs, and produces text outputs (including Structured Outputs). It is the best model for most tasks, and is our most capable model outside of our o-series models.
This is the 9th launch from GPT-4o. View more

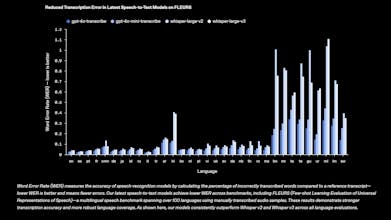
OpenAI GPT-4o Audio Models


New OpenAI audio models for developers: gpt-4o powered speech-to-text (more accurate than Whisper) and steerable text-to-speech. Build voice agents, transcriptions, and more.



Launch Team


















Hi everyone!
Voice is the future, and OpenAI's new audio models are accelerating that shift! They've just launched three new models in their API:
🎤 gpt-4o-transcribe & gpt-4o-mini-transcribe (STT): Beating Whisper on accuracy, even in noisy environments. Great for call centers, meeting transcription, and more.
🗣️ gpt-4o-mini-tts (TTS): This is the game-changer. Steerable voice output – you control the style and tone! Think truly personalized voice agents.
🛠️ Easy Integration: Works with the OpenAI API and Agents SDK, supporting both speech-to-speech and chained development.
Experience the steerable TTS for yourself: OpenAI.fm
Visla
Can it translate voice in real time stream?
@kirill_a_belov Think it's still not a single API call, you'll need to chain together a few different APIs to do real-time translation. STT-LLM(for text translation)-TTS.
@zaczuo Yep. I've heard Apple will have such feature in new air pods.
The alloy and shimmer voices always sounded 10x better than the others. And tbh. Having tried 11labs a lot. Alloy and Shimmer is the bar to beat. Love the testing UX on openai.fm tho. Used to be only able to test these voices in open-ai's internal playground dashboard.
@sentry_co I’ve been working on voice-based AI apps, so I always keep a close eye on AI capabilities in the audio. Clearly, current LLMs still have some way to go in achieving native end-to-end audio processing—handling input without converting to text via ASR and output without generating text before TTS.
After all, humans can listen and speak before learning to read, and even illiterate people communicate just fine in society, right? Speech carries the core of communication, with emotions, tones, and nuances that can’t be fully conveyed when flattened into text.
We might be observing significant progress through more emotional audio output, which helps us refine our understanding of audio input.
Yeah we are 90% there. It's just that the last 10% will take 90% of the effort 😅. Maybe. I do feel that I get the best results with AI voices, when I run the same text a few times over, and then The AI will slightly change on each iteration. Then I cherry pick which segments I like the most from each iteration. And then put it all together. I think this process could be done by an AI tho. Maybe the cherry picking part is hard for an AI, because it doesnt understand which is better.
@sentry_co True. And the rest 10% might bring 90% of the total impact ;)