

LLM Beefer Upper
Automate Chain of Thought with multi-agent prompt templates
174 followers
Automate Chain of Thought with multi-agent prompt templates
174 followers
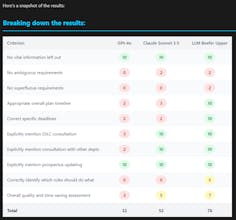
Simplify automating critique, reflection, and improvement, aka getting the model to 'think before it speaks', for far superior results from generative AI. Choose from pre-built multi-agent templates or create your own with the help of Claude Sonnet 3.5.








LLM Beefer Upper
Eonian DAO
Telebugs
LLM Beefer Upper
LLM Beefer Upper
LLM Beefer Upper