
Gestell
ETL for LLMs
15 followers
Gestell is an ETL for LLMs. We transform unstructured data into AI-ready databases through a process that spans from Enframing to Disclosure, enabling accurate, scalable search-based reasoning for your LLM

15 followers
Gestell is an ETL for LLMs. We transform unstructured data into AI-ready databases through a process that spans from Enframing to Disclosure, enabling accurate, scalable search-based reasoning for your LLM









Hi Product Hunt! 👋
We’re the team behind Gestell, and we’re excited to introduce it to you today!
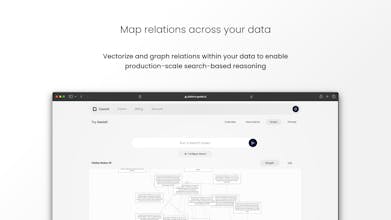
Gestell is a new paradigm for ETLs, an ETL for LLMs. We handle the entire data ingestion and structuring process from chunking, to vectorization, graph creation and more - enabling search-based reasoning at production-scale, in minutes
🎯The problem we are solving:
Scaling a search-based reasoning system for an LLM is incredibly costly and nearly impossible with the current landscape of tools. The current patchworked landscape of RAG tooling is full of point solutions that take months to build and won’t even scale to production-level databases. Your model with PhD level intelligence shouldn’t struggle to understand a database. Gestell fixes this through our integrated ETL that delivers the exact context your model needs, enabling out-of-the-box structuring that will work at scale for use-case
What Gestell does:
🔗End-to-End ETL: the only ETL to handle the entire data ingestion and structuring process for LLMs
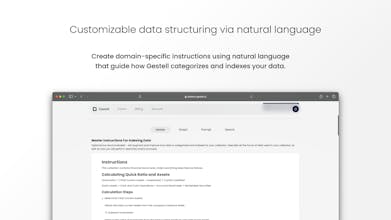
📝Customizable via Natural Language: simply instruct Gestell how to structure your data, and each step will be optimized based upon your query
📈Accurate Scalability: the only structuring platform to scale search-based reasoning accurately on database sizes of 100k+ pages
💰Cost Efficient: Gestell is ~40%+ cheaper than solutions like Google’s Document AI (which only has pdf parsing)
📷 Multimodal: ingest and structure all of your data across 50+ filetypes including documents, audio and video
⚙️Feature Extraction and Table Structuring: optimize specific outputs based upon criteria like the extraction of data features (names, dates, etc.) or structure outputs as a table, with data pulled based upon columns
🔍In-built tooling: chunking, vectorization, graph creation, re-rankers and more
🚀We’ve proven the results:
We are currently best in the world at FinanceBench - at an 88% accuracy, with the closest SOTA competition from Databricks at only ~67% accuracy
First 500 credits (pages) are free - would love to have the Product Hunt community check it out!
Can’t wait to hear your feedback!
Excellent product! Excited to use!