
Cekura enables Conversational AI teams to automate QA across the entire agent lifecycle—from pre-production simulation and evaluation to monitoring of production calls. We also support seamless integration into CI/CD pipelines, ensuring consistent quality and reliability at every stage of development and deployment.

Subscribe
Sign in


















Cekura
Hi Product Hunt Fam 👋 - @kabra_sidhant, @shashij_gupta and @tarush_ here from Cekura AI.
Cekura lets you simulate, evaluate and monitor your Voice & Chat AI agents automatically.
Why did we build Cekura? 💡
Cekura was born out of our own frustration building voice agents for healthcare, where every change required hours of manual QA, yet critical failures still made it to production. We built the platform we wished existed: one that simulates conversations at scale, generates edge-case scenarios, and monitors real-world agent calls for failures.
Team Background 👥
Shashij has published a paper on AI systems testing from his research at ETH Zurich and Google. Tarush has developed simulations for ultra-low latency trading, and I have led product and growth teams before, including a conversational AI company. All of us met at IIT Bombay and have been friends for the last 8 years.
Problem🚨: Making Conversational AI agents reliable is hard. Manually calling/chatting with your agents or listening through thousands of conversations is slow, error-prone and does not provide the required coverage.
Our Solution: At Cekura, we work closely with you at each step of the agent-building journey and help you improve and scale your agents 10 times faster
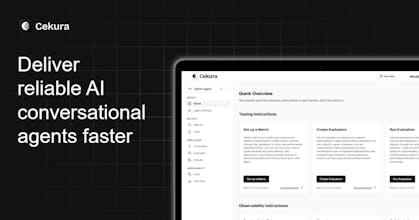
Key Features:
Testing:
Scenario Generation: Create varied test cases from agent descriptions automatically for comprehensive coverage.
Evaluation Metrics: Track custom and AI-generated metrics. Check for instruction following, tool calls, and conversational metrics (Interruptions, Latency, etc).
Prompt Recommendation: Get actionable insights to improve each of the metrics.
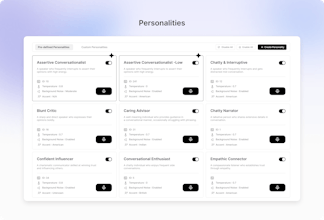
Custom Personas: Emulate diverse user types with varied accents, background noise, and conversational styles.
Production Call & Chat Simulation: Simulate production calls to ensure all the fixes have been incorporated.
Observability:
Conversational Analytics: Provides customer sentiment, interruptions, latency and call analytics: ringing duration, success rate, call volume trends, etc
Instruction Following: Identify instances where agents fail to follow instructions.
Drop-off Tracking: Analyzes when and why users abandon calls, highlighting areas of improvement.
Custom Metrics: Define unique metrics for personalized call analysis.
Alerting: Proactively notifies users of critical issues like latency spikes or missed functions.
Major Updates Since Last Product Hunt Launch:
Added Chat AI Testing and Observability
Automated Expected Outcome along with each generated scenario
Simulation of Production conversations
'Instruction Following' and 'Hallucination' metric to automatically flag deviations from Agent description and Knowledge base respectively
Who is this for?
Anyone building Conversational AI agents. If you want to make your voice & chat AI agents reliable, book my calendar here 🗓️ or reach out to sidhant@cekura.ai📧.
Demo 🎥
You can check out our demo video here.
If you'd like to engage in a fun roleplay, you can talk with our agent here: You will act as a customer support representative and our agent will call you for a refund, order status, and product recommendation. After the call, we will give you an evaluation.
Please note: In reality, we generate hundreds of simulations automatically and provide detailed analytics on your AI agent's performance as demonstrated in the demo video.
Shoutout 🙌
Thanks @garrytan for hunting us. Also @svkpham and @rohanrecommends for helping us with the launch. 🎉
@kabra_sidhant @shashij_gupta @tarush_ @garrytan @svkpham @rohanrecommends Are your evaluations based on audio, text, or both?
Cekura
@kabra_sidhant @shashij_gupta @garrytan @svkpham @rohanrecommends @monia_dohas We break down the evaluations via metrics. We do use both text and audio. Some metrics (e.g., latency, interruptions, sentiment) run on audio, and some metrics which check for instruction following work on text.
OpenFunnel(YC F24)
Congrats on the Launch!
How do you guys see reliability going beyond metrics but being reliable/contextual in domain specific questions and conversations?
Cekura
@fenil_suchak1, you are right. Reliability extends beyond conversational metrics, such as latency and interruptions. Its giving the right answer at every step for company/domain-specific questions as well.
We typically visualize metrics into three types:
Conversational Metrics: applicable across customers across industries
Industry Specific Metrics: applicable across customers for a particular industry. Healthcare: HIPAA compliance, BFSI: PCI DSS compliance
Company specific Metrics: Following company specific SOPs
Cekura
@fenil_suchak1 i think with time we are seeing a lot of improvement in model reliability. Along with that people are using custom logics with asserts, thinking models and nlp logics to make it more reliable
DaoLens
Do you provide alerts for production calls?
Cekura
Yes, @nimishg , we provide alerts for production calls over Slack and Gmail. You can also setup frequency of alerts as daily or as soon as the issue happens, e.g: latency spikes
Cekura
@nimishg yes you can get alerted whenever something critically wrong goes into production